Con muy poquitas modificaciones realizo ahora el seguimiento de dos puntos centrales de la imagen para calcular la rotación (balanceo) de la cámara.
El código de ejemplo es:
Con un par de modificaciones rápidas más (hardcoded) guardo las imágenes obtenidas en un vídeo AVI con FOURCC "XVID", 30 imágenes por segundo y con nombre de archivo "salida.avi". Lo ideal sería calcular la velocidad de cuadro real y/o enviar el mismo fotograma a la salida en caso de ralentización.
Ese tema lo dejaremos para más adelante.
El código de ejemplo modificado es:
En el siguiente vídeo puede observarse el seguimiento del horizonte realizado por el algoritmo.
Hay que recordar que no se hace corrección de perspectiva, por lo que si la webcam no sólo se rota (balancea) si no que se gira o cabecea, el cálculo del balanceo comienza a acumular errores. Por eso en el vídeo reinicio el horizonte en dos ocasiones.
martes, 15 de febrero de 2011
lunes, 14 de febrero de 2011
Análisis del flujo de movimiento en OpenCV (y 2)
He realizado una pequeña modificación para mostrar el movimiento acumulado (y representado por la flecha roja central) mediante una cruz verde.
Aparentemente se sigue el movimiento del punto de la escena, pero sólo funciona si la escena se mueve al mismo tiempo sin rotación y sin que haya un objeto en el centro que se mueva.
El código de ejemplo es:
El resultado de un movimiento satisfactorio (sin rotación ni objetos en la zona central que interfieran) puede verse en el siguiente vídeo:
Pero si realizamos rotación de la webcam o pasamos un objeto por el centro de la escena (pero no delante del objeto perseguido) entonces el algoritmo falla, ya que la información la está obteniendo del centro de la pantalla y no del objeto rastreado:
La forma de arreglar este problema es sencilla. En vez de dejar fijo el punto del fotograma anterior al que queremos calcular el flujo de movimiento lo vamos actualizando al mismo punto donde se ha calculado el desplazamiento.
El código del ejemplo mejorado es:
En el siguiente vídeo se muestra cómo ahora el algoritmo es más robusto frente a la rotación de la imagen, al movimiento de objetos en la zona central, pero no a los movimientos de objetos frente al objeto rastreado:
Aparentemente se sigue el movimiento del punto de la escena, pero sólo funciona si la escena se mueve al mismo tiempo sin rotación y sin que haya un objeto en el centro que se mueva.
El código de ejemplo es:
El resultado de un movimiento satisfactorio (sin rotación ni objetos en la zona central que interfieran) puede verse en el siguiente vídeo:
Pero si realizamos rotación de la webcam o pasamos un objeto por el centro de la escena (pero no delante del objeto perseguido) entonces el algoritmo falla, ya que la información la está obteniendo del centro de la pantalla y no del objeto rastreado:
La forma de arreglar este problema es sencilla. En vez de dejar fijo el punto del fotograma anterior al que queremos calcular el flujo de movimiento lo vamos actualizando al mismo punto donde se ha calculado el desplazamiento.
El código del ejemplo mejorado es:
En el siguiente vídeo se muestra cómo ahora el algoritmo es más robusto frente a la rotación de la imagen, al movimiento de objetos en la zona central, pero no a los movimientos de objetos frente al objeto rastreado:
viernes, 11 de febrero de 2011
Análisis del flujo de movimiento en OpenCV
Vamos a dar un salto brusco en la línea de aprendizaje para llegar al análisis del flujo de movimiento usando la librería de visión artificial OpenCV.
En este ejemplo (algo más complejo que los anteriores) usaremos tres imágenes temporales, el fotograma actual en color sobre el que dibujaremos líneas que representarán el flujo de movimiento y una copia del fotograma anterior y actual en escala de grises, y dos imágenes de trabajo para las dos pirámides necesarias para la implementación piramidal desarrollada por Jean-Yves Bouguet del algoritmo iterativo de seguimiento de características de imagen de Lucas-Kanade.
La función usada es cvCalcOpticalFlowPyrLK.
Tiene como parámetros de entrada los dos fotogramas sobre los que deseamos estudiar el flujo de movimiento (en escala de grises), las dos imágenes temporales (pirámides), una serie de puntos sobre los que deseamos averiguar el flujo de movimiento, el vector de movimiento resultante y el criterio de parada.
El código de ejemplo es (le faltan unos retoques):
Se puede experimentar con diversos criterios de parada (número máximo de iteraciones y error permitido). Si se alcanza el número máximo de iteraciones sin haber llegado a un resultado que se ajuste al error deseado la característica será marcada como no calculada. Esto suele ocurrir, sobre todo, cuando se trabaja con zonas de color liso o durante movimientos bruscos en los que el emborronado de movimiento de la cámara (o webcam) suaviza los detalles de la imagen haciéndolos irreconocibles desde el fotograma anterior.
Por otro lado, os recuerdo que una gran mayoría de webcams entregan los fotogramas en formato JPEG, por lo que para evitar que los artefactos cuadriculados de la compresión JPEG estorben en el análisis de movimientos debe usarse una apertura superior a 16 pixeles.
En este ejemplo (algo más complejo que los anteriores) usaremos tres imágenes temporales, el fotograma actual en color sobre el que dibujaremos líneas que representarán el flujo de movimiento y una copia del fotograma anterior y actual en escala de grises, y dos imágenes de trabajo para las dos pirámides necesarias para la implementación piramidal desarrollada por Jean-Yves Bouguet del algoritmo iterativo de seguimiento de características de imagen de Lucas-Kanade.
La función usada es cvCalcOpticalFlowPyrLK.
Tiene como parámetros de entrada los dos fotogramas sobre los que deseamos estudiar el flujo de movimiento (en escala de grises), las dos imágenes temporales (pirámides), una serie de puntos sobre los que deseamos averiguar el flujo de movimiento, el vector de movimiento resultante y el criterio de parada.
El código de ejemplo es (le faltan unos retoques):
Se puede experimentar con diversos criterios de parada (número máximo de iteraciones y error permitido). Si se alcanza el número máximo de iteraciones sin haber llegado a un resultado que se ajuste al error deseado la característica será marcada como no calculada. Esto suele ocurrir, sobre todo, cuando se trabaja con zonas de color liso o durante movimientos bruscos en los que el emborronado de movimiento de la cámara (o webcam) suaviza los detalles de la imagen haciéndolos irreconocibles desde el fotograma anterior.
Por otro lado, os recuerdo que una gran mayoría de webcams entregan los fotogramas en formato JPEG, por lo que para evitar que los artefactos cuadriculados de la compresión JPEG estorben en el análisis de movimientos debe usarse una apertura superior a 16 pixeles.
lunes, 7 de febrero de 2011
Filtro de detección de bordes (Canny) usando OpenCV
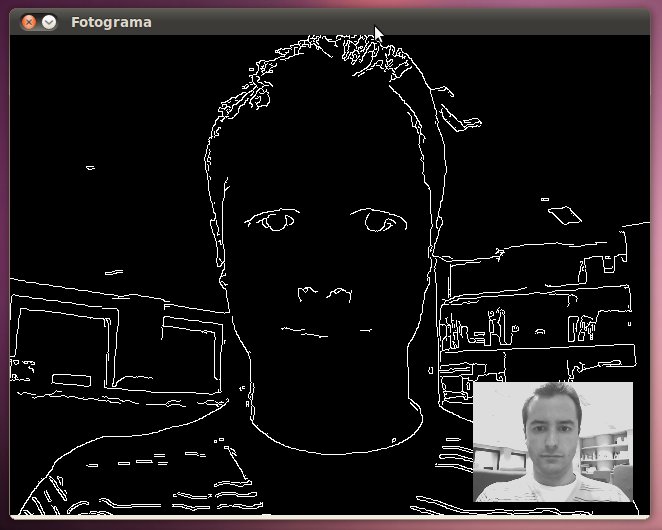
La detección de bordes, en procesamiento digital de imágenes, nos permite averiguar los contornos de la imagen o, mejor dicho, los cambios bruscos de intensidad lumínica. Es por esto último por lo que no se recomienda usar un filtro de detección de bordes tras haber suavizado con una amplitud grande una imagen a no ser que se use una apertura superior en el filtro Canny.
La función que realiza el filtro de suavizado de imagen en OpenCV es cvCanny.
El código fuente del ejemplo es:
El resultado obtenido tras ejecutar el código de ejemplo es:
La función que realiza el filtro de suavizado de imagen en OpenCV es cvCanny.
El código fuente del ejemplo es:
El resultado obtenido tras ejecutar el código de ejemplo es:
martes, 4 de enero de 2011
Filtrado de imagen (suavizado) usando OpenCV
Uno de los problemas más comunes que nos encontramos a la hora de analizar imágenes obtenidas desde dispositivos de captura es el ruido de compresión, cuantización y de sensibilidad del sensor de captura.
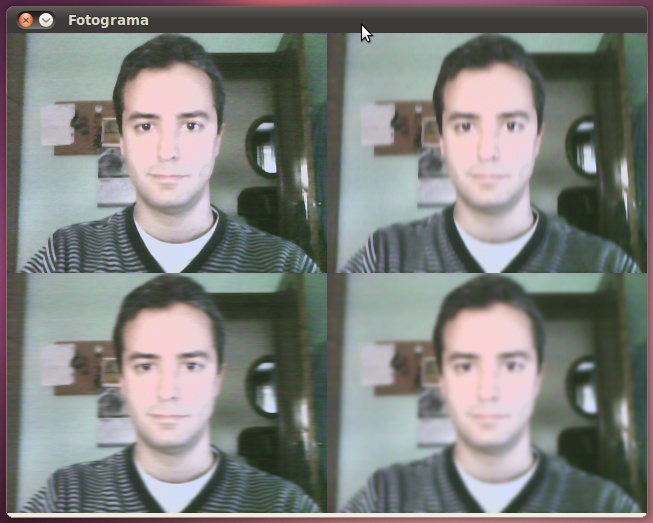
Uno de los métodos existentes para reducir ese ruido es filtrar espacialmente la imagen (suavizado) aunque ello provoque pérdida del detalle de la imagen.
Realizaremos tres ejemplos usando un filtro lineal gausiano (CV_GAUSSIAN) con unos tamaños de 1x9 (filtro de suavizamiento vertical), 9x1 (suavizamiento horizontal) y 9x9 (suavizamiento normal).
La función que realiza el filtro de suavizado de imagen en OpenCV es cvSmooth.
El código fuente del ejemplo es:
El resultado de suavizar horizontalmente la imagen elimina la mayoría del ruido producido por la emisión en el aire de señales de televisión al tiempo que se pierde la definición de las imágenes en forma de columnas verticales.
Tras suavizar verticalmente la imagen se elimina el granulado debido a cuantización y codificación en muchas webcams (observar cómo prácticamente ha desaparecido el ruido en la imagen superior derecha) pero se pierde la definición de las imágenes en forma de filas horizontales (ver cómo prácticamente desaparecen las rayas del jersey).
El mejor resultado de obtiene al filtrar horizontal y verticalmente la imagen, pero al mismo tiempo es cuando se pierde mayor detalle de la imagen.
El resultado obtenido tras ejecutar el código de ejemplo es:
Uno de los métodos existentes para reducir ese ruido es filtrar espacialmente la imagen (suavizado) aunque ello provoque pérdida del detalle de la imagen.
Realizaremos tres ejemplos usando un filtro lineal gausiano (CV_GAUSSIAN) con unos tamaños de 1x9 (filtro de suavizamiento vertical), 9x1 (suavizamiento horizontal) y 9x9 (suavizamiento normal).
La función que realiza el filtro de suavizado de imagen en OpenCV es cvSmooth.
El código fuente del ejemplo es:
El resultado de suavizar horizontalmente la imagen elimina la mayoría del ruido producido por la emisión en el aire de señales de televisión al tiempo que se pierde la definición de las imágenes en forma de columnas verticales.
Tras suavizar verticalmente la imagen se elimina el granulado debido a cuantización y codificación en muchas webcams (observar cómo prácticamente ha desaparecido el ruido en la imagen superior derecha) pero se pierde la definición de las imágenes en forma de filas horizontales (ver cómo prácticamente desaparecen las rayas del jersey).
El mejor resultado de obtiene al filtrar horizontal y verticalmente la imagen, pero al mismo tiempo es cuando se pierde mayor detalle de la imagen.
El resultado obtenido tras ejecutar el código de ejemplo es:
Otro ejemplo de región de interés (ROI) en OpenCV
Para ilustrar mejor el funcionamiento de las regiones de interés (antes de continuar con algoritmos de filtrado de imagen) veremos un último ejemplo sencillo de regiones de interés en el que sólo visualizaremos una línea horizontal de la parte inferior de la imagen (útil para implementar, por ejemplo, algoritmos de robots sigue líneas).
El código del ejemplo es el siguiente:
En este caso lo que hemos hecho ha sido marcar como región de interés (ROI) únicamente la zona inferior de una altura determinada. Al hacerlo estamos diciendo que sólo nos interesa trabajar con esa zona de la imagen, por lo que al mostrar el fotograma sólo veremos la parte inferior seleccionada.
El resultado obtenido (con una altura de 50 puntos de pantalla) es:

El código del ejemplo es el siguiente:
En este caso lo que hemos hecho ha sido marcar como región de interés (ROI) únicamente la zona inferior de una altura determinada. Al hacerlo estamos diciendo que sólo nos interesa trabajar con esa zona de la imagen, por lo que al mostrar el fotograma sólo veremos la parte inferior seleccionada.
El resultado obtenido (con una altura de 50 puntos de pantalla) es:
domingo, 2 de enero de 2011
Mezclando dos imágenes en una con OpenCV
No existe forma directa de mostrar dos imágenes dentro de una misma ventana usando las funciones ofrecidas por OpenCV, pero podemos hacer uso de la región de interés (ROI - Region Of Interest) para conseguirlo.
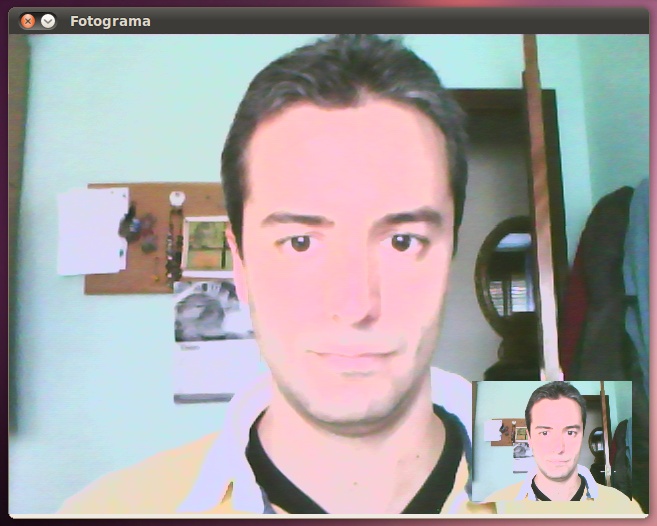
Con las regiones de interés podemos definir a qué parte de una imagen destino queremos "pegar" el contenido de una imagen fuente. De esta manera conseguimos "componer" la imagen destino deseada a partir de todas las imágenes fuentes necesarias.
En el siguiente ejemplo obtendremos un fotograma del dispositivo de captura y lo mostraremos a tamaño completo con una versión en miniatura del mismo fotograma en su interior.
Una cosa muy importante a tener cuando trabajamos con fotogramas capturados usando OpenCV es que no debemos modificar la imagen entregada por cvQueryFrame ni podremos reutilizar la imagen obtenida por sucesivos fotogramas capturados (explicaré mejor esto último en sucesivos ejemplos).
Por este motivo la composición se hará en una imagen clonada a partir del fotograma capturado usando la función cvClone. Tras ello definiremos la región de interés en dicha imagen clonada (el área de destino donde "pegaremos" de nuevo la imagen) y usaremos de nuevo la función cvResize para copiar una versión escalada del fotograma dentro de la región deseada.
Es importante recordar que la función cvClone aloja la memoria necesaria para almacenar tanto la cabecera de la imagen como su contenido, de modo que llamadas sucesivas a dicha función sin liberar los recursos previamente provocará que nuestra aplicación esté continuamente aumentando su consumo de memoria, de modo que no debemos olvidarnos de liberar los recursos reservados mediante una llamada a la función cvReleaseImage.
Código fuente del ejemplo:
Explicación en detalle paso por paso:
El resultado obtenido es:
Con las regiones de interés podemos definir a qué parte de una imagen destino queremos "pegar" el contenido de una imagen fuente. De esta manera conseguimos "componer" la imagen destino deseada a partir de todas las imágenes fuentes necesarias.
En el siguiente ejemplo obtendremos un fotograma del dispositivo de captura y lo mostraremos a tamaño completo con una versión en miniatura del mismo fotograma en su interior.
Una cosa muy importante a tener cuando trabajamos con fotogramas capturados usando OpenCV es que no debemos modificar la imagen entregada por cvQueryFrame ni podremos reutilizar la imagen obtenida por sucesivos fotogramas capturados (explicaré mejor esto último en sucesivos ejemplos).
Por este motivo la composición se hará en una imagen clonada a partir del fotograma capturado usando la función cvClone. Tras ello definiremos la región de interés en dicha imagen clonada (el área de destino donde "pegaremos" de nuevo la imagen) y usaremos de nuevo la función cvResize para copiar una versión escalada del fotograma dentro de la región deseada.
Es importante recordar que la función cvClone aloja la memoria necesaria para almacenar tanto la cabecera de la imagen como su contenido, de modo que llamadas sucesivas a dicha función sin liberar los recursos previamente provocará que nuestra aplicación esté continuamente aumentando su consumo de memoria, de modo que no debemos olvidarnos de liberar los recursos reservados mediante una llamada a la función cvReleaseImage.
Código fuente del ejemplo:
Explicación en detalle paso por paso:
- Obtenemos un fotograma del dispositivo de captura en "fotograma".
- Creamos una copia del fotograma en "copia".
- Seleccionamos una zona de la imagen "copia" sobre la que volcaremos una versión escalada (una miniatura) del mismo fotograma.
- Realizamos el escalado de imagen sobre esa zona de interés.
- Deshacemos la selección de zona para que la función cvShowImage no nos muestre únicamente la región de interés (nos aparecería únicamente la zona recién escalada), si no la composición completa (el fotograma en grande junto con la miniatura.
- Tras mostrar la composición realizada en "copia" liberamos la memoria usada.
El resultado obtenido es:
Escalando el tamaño de un fotograma capturado usando OpenCV
Debido a que algunos algoritmos pueden consumir una cantidad excesiva de CPU impidiendo su ejecución en tiempo real (o, al menos, con una frecuencia de 10 veces por segundo), tenemos la opción de reducir el tamaño del fotograma a unas dimensiones que nos permita trabajar con un mayor número de fotogramas por segundo.
Para ello usaremos la función cvResize (escalado de imágenes).
Aquí tenemos un ejemplo en el que mostramos la imagen obtenida del dispositivo de captura, pero escalada al tamaño deseado:
Para ello usaremos la función cvResize (escalado de imágenes).
Aquí tenemos un ejemplo en el que mostramos la imagen obtenida del dispositivo de captura, pero escalada al tamaño deseado:
Limitaciones en la captura de imágenes con OpenCV
Dependiendo del dispositivo de captura usado, la plataforma sobre la que se compile la aplicación (cada API de cada sistema operativo tiene diferentes limitaciones y ventajas) y el dispositivo de captura usado (no todos los dispositivos admiten cualquier resolución), podremos hacer uso de la configuración del alto y ancho de la imagen (resolución) que deseamos obtener del dispositivo de captura.
Esto nos permitirá, sobre todo, ahorrar ancho de banda del bus al que se encuentre conectado el dispositivo, disminuir el uso de CPU para procesar cierto tipo de imágenes (sobre todo si se trata de una cámara que ofrece unas resoluciones muy elevadas), aumentar el número de imágenes por segundo que podemos obtener del dispositivo, etc.
Para conseguirlo deberemos hacer uso de la función cvSetCaptureProperty para modificar los parámetros CV_CAP_PROP_FRAME_WIDTH (ancho) y CV_CAP_PROP_FRAME_HEIGHT (alto).
Podemos ver cómo hacerlo en el siguiente ejemplo:
Nota: La implementación de V4L2 en OpenCV 2.1 parece estar rota bajo Linux, por lo que falla el cambio de resolución. He encontrado parches para hacerlo funcionar de nuevo, pero confío en que lo arreglarán en breve espacio de tiempo.
Esto nos permitirá, sobre todo, ahorrar ancho de banda del bus al que se encuentre conectado el dispositivo, disminuir el uso de CPU para procesar cierto tipo de imágenes (sobre todo si se trata de una cámara que ofrece unas resoluciones muy elevadas), aumentar el número de imágenes por segundo que podemos obtener del dispositivo, etc.
Para conseguirlo deberemos hacer uso de la función cvSetCaptureProperty para modificar los parámetros CV_CAP_PROP_FRAME_WIDTH (ancho) y CV_CAP_PROP_FRAME_HEIGHT (alto).
Podemos ver cómo hacerlo en el siguiente ejemplo:
Nota: La implementación de V4L2 en OpenCV 2.1 parece estar rota bajo Linux, por lo que falla el cambio de resolución. He encontrado parches para hacerlo funcionar de nuevo, pero confío en que lo arreglarán en breve espacio de tiempo.
Suscribirse a:
Comentarios (Atom)