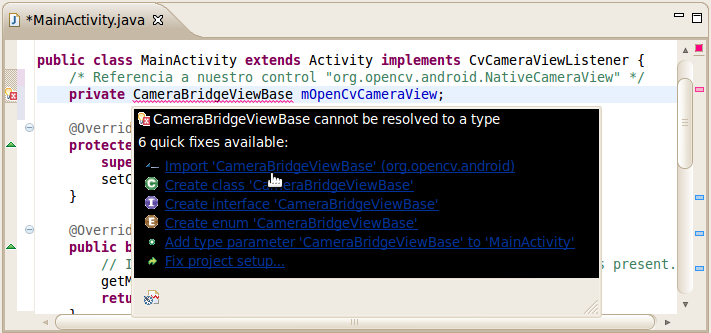
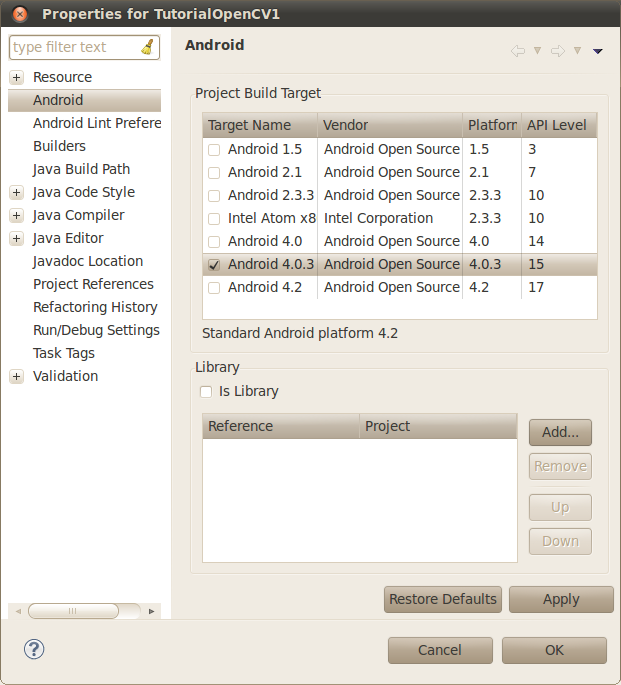
Hace unos días un seguidor del blog me mandó un mensaje por hangouts preguntándome cómo podría detectar si una imagen está negra o no. Rápidamente le propuse una solución (de las muchas posibles). Animado por continuar con el blog decidí implementarlo.
Este es el resultado:
A diferencia de los primeros artículos de este blog, ahora programo mayoritariamente en C++ debido a la influencia que ha ejercido sobre mí la plataforma robótica JdeRobot y el middleware ZeroC ICE (Internet Communications Engine).
Debido a este cambio tendré que hacer un breve repaso de las bases de obtención de fotogramas en C++ que, básicamente, no dista mucho de cómo se hace en C.
Para empezar no se usa una estructura del tipo "IplImage" para almacenar una imagen. En su lugar se usa clase para tratamiento de matrices genérica llamada "Mat". La conversión entre ambos tipos de imágenes es muy sencillo y casi directo.
Otra diferencia significativa aparece a la hora de configurar el dispositivo de captura. En vez de usar la estructura "CvCapture" para almacenar el resultado de la llamada a "cvCaptureFromCAM" usaremos una clase llamada "VideoCapture" cuyo constructor permite seleccionar la cámara de manera directa (facilita el código y su lectura).
Una vez abierto el dispositivo de captura (ésto último se comprueba usando el método "isOpened") podremos obtener imágenes del dispositivo usando el operador sobrecargado ">>".
Por último las funciones C "cvNamedWindow" y "cvShowImage" son sustituidos por los métodos "namedWindow" e "imshow".
Como podéis ver no me gusta usar "namespaces" para ahorrarme usar los prefijos "cv::", "std::", etc. Esto se debe a que no me gusta olvidar qué implementa el método que estoy llamando. Usar "namespaces" complica o dificulta la lectura del código o reconocer fácilmente métodos ajenos y quién los provee.
Una vez explicadas las diferencias básicas entre la implementación C y C++ nos centraremos en el funcionamiento del detector.
Primero convertimos el fotograma obtenido a escala de grises (un único canal con datos enteros sin signo de 8 bits, ):
// Convertimos el fotograma a escala de grises
cv::cvtColor(fotograma, grises, CV_BGR2GRAY);
Con esto facilitaremos la interpretación de la imagen. El histograma es un recuento de cuántos puntos de una imagen tienen el mismo valor para cada uno de sus canales (las imágenes en color tienen tres o cuatro canales, uno azul, otro verde, otro rojo y un último canal opcional que suele usarse para representar la transparencia de dicho punto).
Si hiciéramos el histograma de cada uno de los canales de una imagen en color (R, G, B o bien B, G, R en el orden que prefiere OpenCV) no tendríamos información fiable de la oscuridad de la imagen ya que una imagen que no contiene tonos azules no significa que sea oscura, podría ser un rojo, un verde o una mezcla de ambos que haría fallar nuestro algoritmo. Hacer un cruce de información entre canales complicaría el código y nos haría perder tiempo de proceso que es precioso en el procesamiento de imágenes en tiempo real (25 imágenes por segundo o más).
Una solución sería convertir la imagen a matiz, saturación y brillo (HSV) y calcular el histograma sólo del canal de brillo... pero es que precisamente el canal de brillo coincide con la representación en escala de grises de una imagen, en los que cada punto está representado por su brillo y por ninguna otra característica de color.
Una vez explicado el motivo por el que se usa una imagen en escala de grises seguimos con el cálculo del histograma de la imagen:
// Rango de los valores del canal de escala de grises (0 mínimo, 256 máximo)
float range[] = { 0, 256 };
// Como sólo tenemos un canal (segundo parámetro) sólo ponemos un elemento
const float* histRange = { range };
// Podríamos "cuantizar" a un reducido número de valores para acelerar el algoritmo
int histSize = 256;
// Calculamos el histograma
cv::calcHist(&grises, 1, 0, cv::Mat(), histograma, 1, &histSize, &histRange);
El parámetro "range" (los nombres están en inglés debido a que obtuve el código con un copiar/pegar de la de OpenCV que explica el cálculo de histogramas) limita el rango máximo y mínimo de los valores que contiene el vector. Teóricamente bastaría con poner { 0, 255 } ya que cada punto en una imagen de escala de grises está representado por un número entero de 8 bits que está comprendido entre 0 y 255.
Dejando ese detalle de lado, si pusiéramos en ese rango { 0, 20 } ahorraríamos memoria y tiempo de proceso ya que posteriormente sólo usaremos los primeros 20 valores para averiguar si una imagen es negra o no, pero lo he dejado completo para poder dibujar el histograma completo sobreimpreso en el cada fotograma.
El parámetro histRange tiene un valor por cada canal de la imagen, de modo que podemos tener un rango diferente para cada canal. En nuestro caso sólo tenemos uno, por lo que el array sólo tiene una dimensión y su contenido es el rango anteriormente definido.
El parámetro histSize define el tamaño final que tendrá el histograma. Si hemos dicho que el rango va de 0 a 256 y ponemos un valor de 256 entonces prácticamente no se hará nada (¿un valor se perdería en el camino?), pero si ponemos en histSize un valor de, por ejemplo, 32 entonces el rango de valores de entrada de 0 a 256 se convertirían ("cuantizarían" si castellanizamos el término anglosajón "quantize", o "reducir" si usamos lenguaje algo más coloquial) en tan sólo 32 valores comprendidos del 0 al 31, por lo que un valor 0 de la imagen de entrada se contabilizará en la posición 0 de salida, y un valor 255 de la imagen de ésta contará como un valor en la posición 31 del array de salida, al igual que lo harían los valores 254 y, posiblemente, el valor 253. La documentación no especifica el tipo de redondeo que se usa para convertir un valor de entrada a una posición del array de salida.
(en construcción)